
calcolatore
(o computer, o elaboratore elettronico) Apparecchio o dispositivo utilizzato per l’elaborazione di dati e segnali.
Cenni storici
Le origini
Il desiderio di realizzare uno strumento in grado di compiere operazioni aritmetiche semplici e ripetitive è stato sempre presente nella storia dell’umanità; ne è un esempio l’abaco cinese, inventato tra il 1000 e il 500 a.C. Le prime vere e proprie macchine capaci di eseguire operazioni aritmetiche risalgono al 17° sec.: nel 1642 B. Pascal realizzò la pascalina, una macchina a ingranaggi in grado di eseguire somme su numeri decimali fino a 12 cifre; nel 1671 G. Leibniz concepì una calcolatrice meccanica destinata a eseguire somme e prodotti, che venne realizzata compiutamente nel 1694. Le premesse alla creazione di un moderno c. digitale furono poste durante il 19° sec. con lo sviluppo, tecnologico e speculativo, di tre grandi linee di applicazioni industriali: meccanismi di controllo, circuiti di decisione logica, macchine calcolatrici. Un’idea chiave per arrivare ai moderni c. fu quella relativa alla macchina analitica di C. Babbage (1834), progetto mai realizzato per difficoltà tecniche ed economiche, ma che conteneva straordinarie anticipazioni sulle modalità di funzionamento dei moderni c., tra cui le diverse schede perforate (schede operative e schede variabili) per definire, rispettivamente, la successione di operazioni da eseguire e gli indirizzi di memoria su cui operare. Gli studi legati alla macchina analitica e il conseguente sviluppo delle tecnologie permisero la realizzazione di un integratore analogico (J. Thomson, 1876), di una macchina per il calcolo delle espressioni logiche (A. Marquand, 1885), di una macchina per il calcolo e la presentazione di tabelle (H. Hollerith, 1884), di una calcolatrice meccanica (D. Felt, 1886). Agli inizi del 20° sec. questi dispositivi si perfezionarono ulteriormente: alle macchine tabulatrici furono aggiunti pannelli per le operazioni definibili mediante opportune connessioni elettriche (1902); le schede perforate delle macchine tabulatrici furono modificate per contenere, oltre ai valori alfabetici o numerici, anche simboli di operazioni da effettuare con tali valori (1920). Parallelamente l’attività di ricerca culminò nella definizione della teoria dei servomeccanismi (H.L. Hazen, 1934) e con la presentazione di una metodologia per il progetto logico dei circuiti digitali (C. Shannon, 1937). Di fondamentale importanza nel campo della calcolabilità furono gli studi di A. Turing e E.L. Post, i quali in modo indipendente introdussero nel 1936 due modelli concettuali di elaborazione: la macchina di Turing e il sistema di Post.
I prototipi
I c. progettati e prodotti tra il 1936 e il 1950 erano essenzialmente prototipi, costruiti in esemplari unici, con una grande diversità nelle tecnologie impiegate e nelle architetture proposte; la Seconda guerra mondiale da un lato favorì il finanziamento dei progetti, dall’altro ne limitò i campi di utilizzo e, soprattutto, ritardò la diffusione di importanti risultati e cambiamenti tecnologici. Risalgono a quegli anni l’ASCC (Automatic Sequence Controlled Calculator, noto anche come Harvard Mark I, realizzato nel 1944 dall’IBM; l’ABC (Atanasoff-Berry Computer, dal nome dei due progettisti e realizzatori), creato tra il 1939 e il 1942; l’ENIAC (Electronic Numerical Integrator And Computer), ultimato nel 1945 da J. Mauchly e J.P. Eckert; il Colossus, operativo dal 1943, realizzato da Turing, H.A. Newman e altri colleghi, basato sulle idee dello stesso Turing; l’EDSAC (Electronic Delay Storage Automatic Calculator), primo c. a programma memorizzato, realizzato da M.V. Wilkes e W. Penwick basandosi sullo schema di ENIAC e datato 1949. Nel 1945 J. von Neumann presentò un documento («First draft of a report on the EDVAC») nel quale faceva il punto sullo stato del progetto EDVAC (Electronic Discrete Variable Automatic Computer): questo documento definiva tutte le caratteristiche di un c. elettronico digitale e fu decisivo nel condizionare l’architettura di tutti i c. successivi, fino ai giorni nostri (architettura o modello di von Neumann).
La prima generazione
A partire dal 1951 i c. furono prodotti in più esemplari e commercializzati. L’impatto sull’evoluzione delle tecniche fu notevolissimo. Appartengono alla prima generazione i c. prodotti tra il 1951 e il 1959, caratterizzati dall’impiego di valvole come elementi circuitali attivi; la memoria principale era realizzata con varie tecnologie (linee di ritardo, tubi elettrostatici, tamburi magnetici), più o meno rapidamente rimpiazzate dagli anellini di ferrite; i tempi di accesso alla memoria erano dell’ordine di qualche decina di ms; le memorie ausiliarie (nastri, tamburi e dischi magnetici) erano utilizzate soprattutto come supporto all’I/O (input/output). Il software, durante la prima generazione, era generalmente limitato: i sistemi erano per lo più mono-utente e mono-programma, quindi non vi era la necessità di complessi sistemi operativi e soprattutto l’I/O era usualmente semplificato da routines di libreria (➔). Tutti i c. erano dotati di interpreti ma anche di assemblatori e compilatori (➔). L’UNIVAC I della Eckert-Mauchly Co., il primo c. di questa generazione, fu consegnato nel marzo del 1951 all’Ufficio del censimento americano: tra il 1951 e il 1958 ne furono venduti 46 esemplari. Gli ultimi modelli cominciavano a presentare caratteristiche che diventeranno importanti nella generazione successiva.
La seconda e la terza generazione
Anche se l’intervallo di tempo 1959-64 definisce in maniera imperfetta la seconda generazione, le caratteristiche tecniche sono invece individuabili in maniera molto netta: gli elementi circuitali attivi erano realizzati a transistori e la memoria era a nuclei di ferrite, con tempi di accesso tra 2 e 10 ms. Dell’epoca furono i c. della Philco Corporation (Transac S-2000, M-211 e M-212) e quelli dell’IBM (709TX, 7090 e 7094). Il progresso nelle tecnologie dei circuiti integrati rese rapidamente obsoleti i c. basati su transistori.
Con la presentazione sul mercato della serie 360 dell’IBM, datata 1964 si indica l’inizio della terza generazione, caratterizzata da un sempre maggiore utilizzo dei circuiti integrati come elementi di circuito, come dispositivi di memoria, per la realizzazione di unità funzionali e in sostituzione di alcune parti di software. I cicli di memoria erano compresi tra qualche decina di ns e qualche ms. A partire dal 1968 ci fu un crescendo nello sviluppo dei minicalcolatori che raggiunsero rapidamente prestazioni paragonabili a quelle dei c. tradizionali.
Per quanto concerne l’architettura, venne usata in modo esteso la microprogrammazione (che permetteva fra l’altro di potenziare a basso costo le istruzioni macchina, l’indirizzamento e l’emulazione di altre architetture); furono introdotti i concetti di memoria virtuale, memoria interleaved, memoria cache (che permettevano di aumentare la velocità di ciclo della memoria e lo spazio di indicizzazione); si svilupparono c. paralleli, multiprocessori, pipeline, reti di c.; i sistemi operativi migliorarono; fu standardizzata la multiprogrammazione; furono introdotti time-sharing e macchine virtuali.
La quarta generazione
Se ne colloca l’inizio intorno al 1980; in effetti dal 1970 sono stati prodotti vari supercalcolatori particolarmente interessanti non solo per le prestazioni, ma soprattutto per il tentativo di superare i limiti intrinseci nel modello di von Neumann. La densità di integrazione dei circuiti che caratterizza questa generazione (fino a milioni di componenti in un chip di alcuni millimetri di lato) non rivoluzionò solo la tecnologia costruttiva dei grandi c., ma trasformò completamente la produzione dei piccoli c. e dei personal computer (PC). Si ebbe l’immissione sul mercato di PC e di workstations con prestazioni paragonabili o superiori ai grandi calcolatori della generazione precedente. Il microprocessore e i suoi derivati diventarono i componenti basilari per la realizzazione dell’hardware dei c.; le memorie a stato solido di grande capacità e basso costo permisero di realizzare PC con memoria centrale di molti Mbit; le dimensioni ridotte e la conseguente ridotta lunghezza delle linee di interconnessione consentirono tempi di clock dell’ordine di decine di MHz. A questa generazione appartengono il primo PC IBM, datato 1981; il Commodore 64, prodotto nel 1982; Lisa, della Apple, primo c. con interfaccia grafica (1983).

La quinta generazione
Sono sempre state le rivoluzioni tecnologiche (valvole, transistor, circuiti integrati e microprocessori) ad aver creato nuove generazioni di c.: da questo punto di vista la quarta generazione non è ancora terminata. Si parla spesso di quinta generazione di c. perché la miniaturizzazione dei componenti ha aperto nuovi orizzonti e reso possibili nuove applicazioni dei c., ormai integrati in una miriade di dispositivi e utilizzati per le funzioni più disparate: si parla di ubiquitous computing o pervasive computing (lett. «elaborazione molto diffusa» ed «elaborazione dilagante»). La miniaturizzazione ha permesso di realizzare c. con CPU (➔; Central Processing Unit) sempre più veloci, che sorpassano i 4 GHz per ciclo di clock, e memorie centrali sempre più performanti, che arrivano a diversi GB (fig. 1).
Definizioni
I c. costituiscono una classe di apparati di varia complessità e struttura in grado di effettuare operazioni (matematiche e/o logiche) su un insieme di informazioni (opportunamente rappresentate mediante dati), in modo da produrre altre informazioni (anch’esse rappresentate da dati), secondo le istruzioni di un programma che determina le regole di derivazione dei risultati a partire dai dati iniziali. Nati come strumenti per eseguire calcoli numerici complessi e ripetitivi, i c. hanno successivamente esteso il loro dominio di applicazione a ogni tipo di controllo e di elaborazione di segnali, segni, informazioni.
C. analogico
Strumento le cui informazioni sono rappresentate mediante dati analogici e il cui programma è realizzato mediante circuiti appositamente studiati e interconnessi (➔ calcolatrice).
C. digitale o numerico
Quello in cui i dati e le istruzioni sono codificati in forma numerica, usualmente in base 2 o in base 10. I calcolatori digitali possono essere sia di tipo general purpose («non specializzato»), ossia utilizzabili per un’ampia gamma di applicazioni, sia specializzati (o dedicati) per particolari applicazioni di tipo scientifico, industriale o commerciale, o per particolari operazioni di tipo logico-matematico.
C. elettronico
Quello in cui i dati sono codificati mediante impulsi elettrici e in cui le operazioni sono effettuate mediante circuiti integrati.
C. di processo, o di controllo
È progettato specificatamente per il controllo di un particolare processo industriale, produttivo ecc.; la specificità dell’applicazione fa sì che il programma debba essere alterato raramente, quindi spesso si tratta di un c. in cui il programma è registrato su di un supporto di sola lettura (ROM).
C. seriale
Quello in cui l’esecuzione di un programma è realizzata eseguendo una istruzione alla volta, su di un dato alla volta.
C. parallelo
Quello in cui possono essere eseguite più istruzioni contemporaneamente: sia la stessa operazione su più di un dato, sia più operazioni sullo stesso dato.
Struttura generale
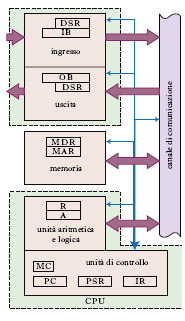
Nonostante le notevoli differenze, nelle prestazioni e nei costi, dei vari tipi di c. che sono stati e sono attualmente presenti sul mercato e l’impressionante sviluppo della tecnologia dei componenti, la struttura generale di un c. elettronico digitale general-purpose è rimasta sostanzialmente invariata e si può descrivere in termini di poche unità il cui schema e le cui relazioni funzionali sono mostrate in figura (fig. 2).
Memoria o memoria interna o memoria principale (main memory)
Unità che contiene i dispositivi necessari a memorizzare tutte le informazioni pertinenti a una determinata elaborazione. Da un punto di vista logico queste informazioni si possono dividere in due categorie: i dati, che costituiscono l’oggetto e il prodotto dell’elaborazione; le istruzioni, che definiscono le regole secondo cui l’elaborazione deve procedere. La quasi totalità dei c. si basa sullo schema organizzativo, proposto nel 1946 da von Neumann, che prevede un’unica memoria per accogliere sia i dati sia le istruzioni e per giunta la possibilità di trattare le istruzioni come fossero dati e viceversa. In particolare, il programma può modificare qualsiasi dato contenuto in memoria, anche se rappresenta un’istruzione del programma stesso; in questo schema è forse contenuta una delle ultime distinzioni possibili tra un c. elettronico digitale e certe calcolatrici tascabili programmabili. Ciascuno dei dispositivi di cui è costituita la memoria è in grado di registrare le cifre del sistema di numerazione adottato nel c.; in particolare, in un c. binario i dispositivi memorizzano le cifre 0 e 1, cioè un bit di informazione. Il valore di questi bit non viene mai alterato o conosciuto singolarmente; essi, e i circuiti che li memorizzano, sono raggruppati in insiemi ordinati, detti parola (in inglese word; il numero di bit in una parola dipende dal tipo e dalla marca del c.; attualmente i c. utilizzano parole di 16, 32 o 64 bit) o byte (formato da 8 bit). A ciascuna parola o byte viene fatto corrispondere un numero progressivo, unico per ciascun elemento, che ne individua la posizione nella memoria e ne costituisce l’indirizzo. Una parola o un byte risultano così la minima quantità di informazione direttamente accessibile; ogni dato o istruzione viene memorizzato in una o più parole. L’unità di memoria è completata da un dispositivo di accesso che permette di effettuare le operazioni di lettura e scrittura; esso consiste, nella sua forma schematica, in due registri e due segnali di controllo. Questi registri sono usualmente indicati con le sigle MAR (Memory Address Register) e MDR (Memory Data Register). Un’operazione di lettura/scrittura si realizza facendo assumere al MAR il valore dell’indirizzo della parola selezionata per il trasferimento e, successivamente, inviando un segnale di controllo che provocherà la copia di tutti i bit: dalla parola indirizzata all’MDR, in lettura; dall’MDR alla parola, in scrittura. Parametri caratteristici di una memoria sono: la lunghezza, in bit, delle parole; la capacità totale, misurata in bit (o meglio, in multipli di bit); il numero di bit del MAR, da cui dipende il massimo numero di parole o byte che possono essere indirizzati; il tempo di accesso, cioè il tempo necessario per effettuare un’operazione di lettura/scrittura, la durata del ciclo di memoria, cioè il tempo minimo che deve intercorrere tra due successive operazioni.
Unità aritmetica e logica (ALU)
È costituita dai dispositivi e circuiti necessari per realizzare le operazioni elementari aritmetiche (somma, sottrazione, moltiplicazione e divisione) e logiche (confronto, OR, AND e complementazione), l’accumulatore A, un certo numero di registri R, necessari a contenere gli operandi, gli eventuali risultati parziali, il risultato finale.
Unità di controllo
L’insieme dei circuiti che garantiscono il corretto funzionamento dell’intero sistema e il necessario sincronismo tra le varie componenti. Mediante un orologio principale (➔ clock), l’unità di controllo scandisce gli intervalli di tempo per l’esecuzione delle varie fasi che compongono il ciclo del c. o ciclo di macchina. Un contatore di programma, PC (Program Counter), serve a realizzare l’esecuzione successiva di tutte le istruzioni che compongono il programma. Mediante un registro di istruzione, IR (Instruction Register), che contiene il codice operativo dell’istruzione in corso, l’unità di controllo invia i segnali per attivare gli opportuni circuiti della ALU. Mediante un registro di stato del programma, PSR (Program Status Register), riceve notizie sull’esito e sulla liceità della istruzione in esecuzione. Il ciclo di macchina è costituito da due fasi principali: la fase di fetch («alimentazione»), in cui l’unità di controllo viene alimentata con l’istruzione o le istruzioni da eseguire, e la fase di esecuzione, in cui l’istruzione (operazione aritmetica, salto ad altra istruzione ecc.) viene eseguita segnalando eventuali errori di esecuzione. L’unità di controllo e l’ALU, con i registri, costituiscono la CPU.
Unità di ingresso/uscita o dispositivi di I/O
Sono dispositivi che permettono la comunicazione tra il c. e l’ambiente esterno, consentono l’immissione di programmi e dati, l’emissione dei risultati. Il compito dei dispositivi di I/O è duplice; essi devono infatti effettuare una conversione tra le grandezze fisiche (usualmente tensioni o correnti elettriche) che rappresentano i dati all’interno del c. e le grandezze fisiche (segni tipografici, magnetizzazione di un nastro magnetico, burning di un CD/DVD, posizione e intensità di un fascio di elettroni di un CRT ecc.), dipendenti dal particolare dispositivo, che rappresentano gli stessi dati all’esterno del calcolatore. Devono inoltre fornire una memoria di transito (➔ buffer) che permetta di raccogliere dati a intervalli di tempo irregolari e di sincronizzarne, poi, il trasferimento da e verso la memoria del calcolatore.
Il panorama dei dispositivi di I/O disponibili attualmente sul mercato è molto ampio, comprendendo dispositivi di estrema sofisticazione (per es. i dispositivi in grado di riconoscere direttamente la voce umana o la grafia) e specializzazione (per es. i terminali dei servizi di cassa automatica delle banche). Si possono comunque raggruppare in tre grandi categorie, in funzione del tipo di ambiente che devono mettere in comunicazione con il c.: dispositivi in cui i dati in ingresso/uscita sono disponibili su di un supporto e in una forma conveniente all’immediato utilizzo da parte dell’uomo (stampanti, plotter ecc.); dispositivi in cui i dati in ingresso/uscita sono disponibili in forma conveniente al controllo di apparati industriali e attrezzature di laboratorio (sensori, convertitori analogico/digitali, analizzatori multicanali ecc.); dispositivi (nastri magnetici, dischi ecc.) in cui i dati sono registrati in forma conveniente allo scambio di informazioni tra differenti c. ovvero in forma idonea a successive elaborazioni sullo stesso c.; in quest’ultimo caso i dispositivi di I/O si possono immaginare come una sorta di memoria (memoria ausiliaria o memoria di massa) esterna al calcolatore. L’insieme dei dispositivi di I/O di un c. ne costituisce la periferia, così detta per la particolare collocazione nella struttura logica e nella disposizione fisica.
Canale di comunicazione
L’insieme dei dispositivi necessari a trasmettere i dati tra le varie unità non può essere localizzato in un oggetto definito, ma, piuttosto, è distribuito su tutta la struttura fisica del c. dalla periferia alle unità centrali. La struttura, più semplice concettualmente, per permettere il colloquio tra n dispositivi è costituita da n(n−1) connessioni unidirezionali tra ciascun dispositivo e tutti gli altri; così come era realizzata, fino a qualche tempo fa, la connessione tra gli utenti del telefono. In questa struttura il numero di connessioni e, soprattutto, il numero di incroci diventa proibitivo al crescere di n e si preferisce, in gran parte delle applicazioni, utilizzare un sistema di linee di trasmissione bidirezionali, detto bus, che collegano tra di loro tutti i dispositivi che possono essere interessati (sia come sorgenti sia come destinatari) nella trasmissione dei dati; alcune di queste linee servono a trasportare dati, le altre i segnali di controllo e sincronismo e un codice (indirizzo della periferica) che identifica il dispositivo destinatario del dato presente a un certo istante, tra tutti quelli affacciati sul bus.
Architettura di un calcolatore
L’architettura di un c. è l’insieme degli elementi di progetto, hardware e software, che ne caratterizzano la struttura logica; lo individuano come appartenente a una determinata classe, famiglia o serie, ne definiscono le potenzialità e i campi di utilizzo. Dal 1950 l’evoluzione delle architetture si è accompagnata allo sviluppo delle tecnologie per diminuire costantemente il rapporto costo/prestazioni.
Lunghezza della parola
È condizionata dalle esigenze contrastanti di memorizzare valori numerici con un sufficiente numero di cifre significative, di manipolare efficientemente i singoli caratteri di stringhe di lunghezza arbitraria, di memorizzare tutte le componenti di ciascuna istruzione (codice operativo, registri, modo di indirizzamento, indirizzo dell’operando ecc.).
Formato delle istruzioni
È condizionato dalla lunghezza della parola, dal numero di possibili istruzioni e dal numero di indirizzi necessari a specificare gli operandi. Per una migliore efficienza di funzionamento un’istruzione dovrebbe essere interamente contenuta in una parola, in modo da poter essere trasferita nell’unità di controllo in un solo ciclo di memoria; l’istruzione deve comunque prevedere due campi principali, di lunghezza adeguata a rappresentare il codice operativo e gli indirizzi. Le istruzioni elementari che un c. deve essere in grado di eseguire comprendono: il trasferimento dei dati tra la memoria e i registri dell’unità centrale; operazioni aritmetiche e logiche sui dati, controllo, interruzioni e salti della sequenza delle istruzioni; operazioni di I/O. Con l’incremento della potenza delle unità centrali di elaborazione, vi è stata una generale tendenza ad aumentare il numero e la complessità delle istruzioni elementari; tale aumento ha portato a una riduzione della compatibilità fra c. e tempi di esecuzione più lunghi, per consentire l’esecuzione delle istruzioni più complesse. Per ovviare a tali inconvenienti, verso la metà degli anni 1980 sono state proposte varie architetture basate su un ristretto numero di istruzioni elementari il più possibile standardizzate; la più nota è l’architettura RISC (Reduce Instruction Set Computer) sviluppata presso la University of California di Berkeley.
Organizzazione della memoria
I differenti rapporti costo/prestazioni delle diverse tipologie di memoria ha portato a un utilizzo gerarchico della memoria stessa del c., che ne utilizza una piccola (circa 1 MB) cache, velocissima e molto costosa, una buona (1-2 GB) RAM, veloce e costosa, e un grande disco (anche diverse centinaia di gigabyte), lento ma poco costoso. Per quanto riguarda la memoria centrale, la sempre migliore organizzazione della memoria di un c., sia dal punto di vista logico sia dal punto di vista circuitale, ha permesso di sfruttarne meglio le possibilità e di ottenere un rapporto costo/prestazioni sempre migliore, al passo con l’evoluzione delle tecnologie elettroniche. Attualmente il tempo di accesso è di 10-20 ns. Anche la capacità, che ormai è limitata più dalla circuiteria per l’indirizzamento che dal volume occupato dalle informazioni, è passata dai circa 9 kbit del primo calcolatore funzionante a programma memorizzato (EDSAC) fino a qualche gigabyte nei c. attuali. Viene gestita dinamicamente, cioè la memoria viene divisa in pagine (o segmenti) che vengono assegnate dinamicamente ai programmi in esecuzione; un programma in esecuzione non viene caricato per intero in memoria, ma viene caricata solo la porzione necessaria per procedere con l’elaborazione, rimandando il caricamento di ulteriori porzioni al momento in cui ciò è realmente necessario.
Struttura dell’unità centrale
Per aumentare le prestazioni delle linee di sviluppo delle unità di controllo e delle unità aritmetiche e logiche, l’unità centrale è stata strutturata in unità funzionali, specializzate, progettate e realizzate per assolvere un determinato compito. Così, per es., esistono unità per la moltiplicazione, la divisione, l’addizione e la sottrazione in virgola mobile e altre unità per le stesse operazioni in virgola fissa: la specializzazione di ciascuna unità permette di ottenere il massimo delle prestazioni. Un’altra tecnica consiste nel fornire l’unità centrale di lungimiranza (look-ahead), dotandola dei dispositivi necessari ad anticipare l’esecuzione per quanto sia possibile prevedere: un buffer interno all’unità di controllo permette di immagazzinare n istruzioni e, quindi, l’unità di controllo può acquisire fino a n istruzioni (fetch-ahead), approfittando di ogni momento in cui sia libero l’accesso in memoria. Inoltre, conoscendo n istruzioni, il c. può iniziare e far progredire l’esecuzione di più di una istruzione per volta (pipelining; ➔ parallelismo). Infatti, per es., l’unità di controllo può recuperare dalla memoria l’istruzione n5, mentre decodifica l’istruzione n1, mentre calcola l’indirizzo dell’operando dell’istruzione n2, mentre esegue l’operazione dell’istruzione n3, mentre deposita in memoria il risultato dell’istruzione n4; così, anche se un’istruzione ha bisogno di un determinato tempo t per essere eseguita, l’unità centrale ne può accettare una ogni frazione di t e, parimenti, produrre un risultato ogni frazione di t. Questo meccanismo è efficace sotto tre ipotesi: che nessuna istruzione modifichi le altre già presenti nel buffer; che nessuna istruzione faccia riferimento a registri che altre istruzioni stanno modificando; che nessuna istruzione alteri il flusso sequenziale del programma. Queste condizioni sono sempre verificate se si tratta di istruzioni di differenti programmi indipendenti e, di conseguenza, questa tecnica è particolarmente utile per c. in multiprogrammazione. Anche se il tempo per l’elaborazione di un singolo programma non è abbreviato, in circa lo stesso tempo si ottiene l’elaborazione di più programmi differenti.
Metodologie e tecniche di comunicazione
Nei primi c. la comunicazione tra le differenti unità avveniva mediante un sistema di linee elettriche che stabilivano la connessione tra i vari punti e tutto il controllo del traffico era completamente a carico dell’unità centrale. Il primo progresso sostanziale si è ottenuto dotando le unità periferiche di una certa aggressività, cioè dei circuiti necessari a informare l’unità di controllo della volontà di iniziare una trasmissione e ottenere, di conseguenza, l’interruzione del programma in esecuzione e l’attenzione dell’unità centrale. Il secondo passo si è ottenuto dotando ciascuna periferica, o gruppi di periferiche, di un’unità di controllo autonoma, in grado di effettuare il trasferimento dei dati senza bloccare l’unità di controllo o l’unità aritmetica e logica. Questo sistema di trasferimento autonomo (canale) viene inizializzato dall’unità centrale con le informazioni di quante parole devono essere trasferite e l’indirizzo della prima; il programma del canale è in grado di calcolare gli indirizzi successivi, memorizzare le parole in un buffer, contarle e trasferirle utilizzando accessi alla memoria principale (porti) diversi e indipendenti da quelli utilizzati dall’unità centrale. Inoltre i canali di comunicazione sono diventati sempre più complessi, anche se non strutturalmente differenti, per poter fornire i numerosi accessi contemporanei, necessari per realizzare la sovrapposizione di differenti fasi dell’esecuzione.
Strutture per elaborazioni parallele
La maggior parte dei c. in funzione oggi sono basati sullo schema per il progetto di EDSAC realizzato da M. Wilkes, che prese spunto da un’idea di J. von Neumann, schema che implica un’elaborazione sequenziale, di un’istruzione alla volta, con dati recuperati dalla memoria o immagazzinati in essa, uno alla volta sequenzialmente. I miglioramenti nelle prestazioni sono ottenuti ottimizzando questo schema. Accanto a esso si sono sviluppate architetture che non considerano il singolo dato o istruzione, ma un insieme di dati o un insieme di istruzioni, come unità di elaborazione. Il parallelismo può essere sia sincrono (operazioni e comunicazioni svolte in parallelo, comandate dal clock di sistema), sia asincrono (c. separati, eventualmente con memoria condivisa, che svolgono operazioni in parallelo comunicandosi i risultati, per es. tramite messaggi). Le architetture dei c. paralleli vengono raggruppate in tre grandi categorie a seconda che il parallelismo si riferisca principalmente ai dati, alle istruzioni o si estenda a entrambi:
a) architetture SIMD (Single Instruction On Multiple Data): c. vettoriali in grado di manipolare le componenti di un vettore con una singola istruzione;
b) architetture MISD (Multiple Instruction Single Data): realizzate mediante una schiera di c. (array of processors), in grado di effettuare contemporaneamente differenti operazioni sugli stessi operandi;
c) architetture MIMD (Multiple Instruction on Multiple Data): c. multiprocessore o multicomputer; nel caso di c. paralleli sincroni si tratta di c. in cui tutte le tecniche di pipelining, di accessi multipli in memoria, di molteplici unità funzionali, di molteplici unità centrali e banchi di memoria, vengono sfruttate per realizzare molteplici operazioni su ciascuna componente di un vettore. Fino alla metà degli anni 1970, i c. di questa classe sono stati costruiti essenzialmente come esemplari unici per centri di ricerca; dalla fine di quel decennio hanno cominciato a essere commercializzati.
La scienza dei calcolatori
Il c. elettronico si colloca, nella ricerca scientifica e tecnologica, sia come oggetto di ricerche e sviluppo, sia come strumento per lo sviluppo di nuove metodologie, nelle più diverse discipline. La distinzione tra i due ruoli è spesso labile e talvolta artificiosa; non è infatti possibile discriminare quanto la richiesta per applicazioni sempre più esigenti abbia spinto l’indagine speculativa sulle strutture dei c. e quanto invece quest’ultima abbia permesso di trovare risposte a problemi sempre più complessi. Uno dei maggiori meriti della scienza dei c. è stata la diffusione di questo strumento – considerato quasi un simbolo di tecnologia sofisticata e in rapida evoluzione e, come tale, dominio esclusivo di tecnici esperti e di alta specializzazione – a categorie di utenti sempre più ampie e sempre meno specializzate, provocando un impatto sociale notevole.
Campi di interesse
La scienza dei c. si occupa dello studio dei meccanismi per la rappresentazione, trasmissione e manipolazione delle informazioni. Un c. digitale permette di costruire modelli di qualsiasi processo purché opportunamente formalizzabile; realizzato che sia questo modello, esso può essere rappresentato in forma di programma e può così essere analizzato e seguito in ogni dettaglio. A seconda del tipo di processo considerato, la scienza dei c. può ricoprire tematiche tipiche di altri settori disciplinari; una sua caratteristica è privilegiare gli aspetti relativi all’uso del c. e quindi alla manipolazione delle informazioni per la rappresentazione, l’analisi e il controllo del processo considerato. Il materiale su cui si fonda la scienza dei c. è quindi formato da: sistemi di elaborazione, procedure e modelli di sistemi informativi, esperienza operativa; esso è utilizzato sia per l’educazione del personale interessato ai c. formando una base logica e un sistema di riferimento alle linee di sviluppo del progetto e delle applicazioni di nuovi strumenti di elaborazione, sia per l’educazione di personale addetto ad altri settori che usano i calcolatori. Inoltre lo studio dei processi informativi che si presentano in natura (per es. i meccanismi di percezione e apprendimento, nell’uomo e negli animali) suggerisce nuove soluzioni e prospettive alla scienza dei c. che, d’altro canto, è in grado di fornire modelli e schemi per la loro comprensione.
Obiettivi e attività
Gli obiettivi possono essere raggruppati in due grandi categorie: analisi dei sistemi di elaborazione, applicazioni dei calcolatori. Appartiene alla prima categoria la realizzazione di strutture, meccanismi e schemi concettuali per lo studio, valutazione e descrizione dei processi di informazione; appartiene alla seconda categoria lo sviluppo delle procedure e metodologie per l’elaborazione delle informazioni e la definizione di strutture adeguate che le rappresentino.
Le applicazioni dei c. sono, usualmente, suddivise in due classi principali:
a) numeriche, in cui l’aspetto numerico dei dati è prevalente (calcolo numerico, simulazione, ottimizzazione);
b) non numeriche (calcolo letterale, manipolazione di simboli, archiviazione e recupero delle informazioni, ottimizzazione combinatoria).
I sistemi di elaborazione possono essere analizzati da un punto di vista software, in cui l’enfasi è data alla rappresentazione dei problemi e dei dati nell’interno del c. e da un punto di vista hardware, in cui l’enfasi è invece data all’organizzazione del c. e al suo progetto logico e circuitale. Le principali attività consistono: nell’analisi dei sistemi, con la costruzione di modelli concettuali per la comprensione e razionalizzazione del materiale disponibile; nella sperimentazione di nuovi sistemi e applicazioni; nella verifica di nuovi concetti e teorie. Più specificatamente gli argomenti della scienza dei c. sono: la rappresentazione formalizzata di problemi, dati e procedure; la teoria della computabilità e l’analisi degli algoritmi; lo studio e l’applicazione di linguaggi evoluti orientati a specifiche classi di problemi; la definizione di schemi per la strutturazione dei dati, delle procedure e di quanto permette di definire il dialogo uomo-c.; la definizione dei linguaggi macchina, degli schemi di memorizzazione delle informazioni e dei meccanismi di programmazione; la costruzione di schemi di organizzazione dei sistemi, di meccanismi esecutivi e di controllo; la teoria dei linguaggi formali e la teoria degli automi.
Calcolatori quantistici
Si tratta di c. il cui funzionamento è basato sui principi della meccanica quantistica. Mentre per un c. odierno l’unità di informazione, il bit, fisicamente corrisponde a un sistema (per es., un atomo) con due soli stati distinti rappresentati formalmente dai due valori logici 1 e 0, il bit quantistico, o qbit, possiede proprietà molto diverse: in meccanica quantistica, infatti, lo stato di un sistema è descritto dalla sovrapposizione coerente dei suoi autostati (nel caso del qbit indicati dai valori 0 o 1); a causa di ciò, lo stato di un sistema formato anche da pochi qbit di un c. quantistico (per es., l’equivalente di un registro di memoria di un c. classico) è caratterizzato dal fatto di poter contenere un numero enorme di informazioni e l’elaborazione, corrispondente all’evoluzione temporale del sistema quantistico, avviene simultaneamente per tutta l’informazione contenuta nel sistema in una modalità che, utilizzando una terminologia informatica classica, si potrebbe definire di calcolo parallelo. Malgrado l’enorme sviluppo degli studi sull’argomento, la possibilità di realizzare un c. quantistico deve ancora essere provata.