
còdice genètico
còdice genètico Relazione esistente tra la sequenza di basi azotate del DNA di un gene e la sequenza di amminoacidi di una proteina. Il DNA contiene 4 diversi nucleotidi che devono codificare i 20 amminoacidi delle proteine; ciò può avvenire in quanto gli amminoacidi vengono determinati da triplette di nucleotidi, dette codoni, con 64 possibili combinazioni di triplette. Alcune di queste non codificano amminoacidi, ma hanno la funzione di interrompere l’informazione: si chiamano codoni di arresto e sono i codoni UAG o amber, UAA o ochre, UGA o opale. Il codice genetico è stato definito universale perché ciascun amminoacido è codificato dalle stesse triplette in ogni organismo vivente e in tutti gli organismi studiati, dai virus all’uomo, non è stata raccolta alcuna prova di qualche modificazione evolutiva nel significato dei 64 codoni possibili.
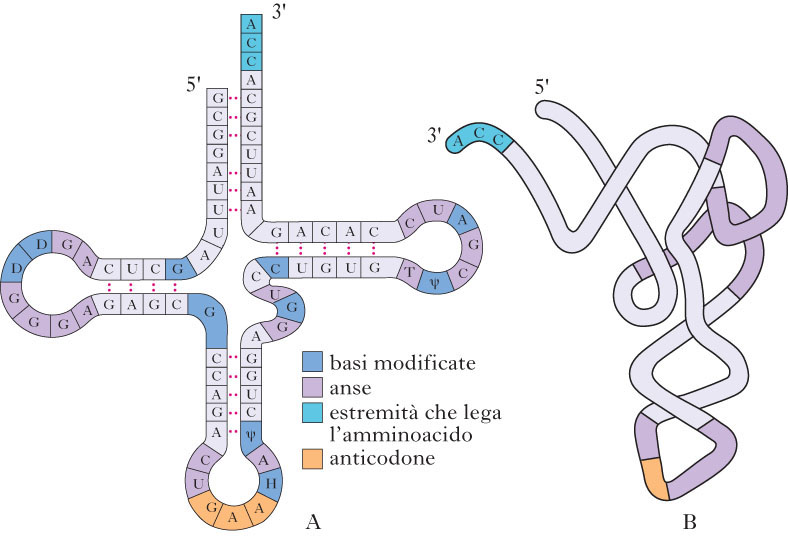
L’informazione genetica contenuta in ogni cellula si trasmette da una generazione all’altra attraverso le interazioni di appaiamento di basi complementari. Essa si esprime tramite la traduzione della sequenza lineare dei nucleotidi del DNA nella sequenza co-lineare degli amminoacidi delle proteine. Inizialmente il cistrone o gene è trascritto in un filamento complementare di RNAm che è poi tradotto in una proteina mediante una reazione catalizzata al livello dei ribosomi. Gli amminoacidi specifici sono trasportati da molecole di tRNA o sRNA, ciascuna delle quali riconosce, mediante l’appaiamento di basi complementari, un gruppo di 3 nucleotidi dell’RNAm, il codone (➔ proteina). Poiché dei 64 codoni, tolti i 3 di arresto che non codificano, ne rimangono 61 per specificare solo 20 amminoacidi diversi, la maggior parte degli amminoacidi è corrispondente a più di un codone. Per questo motivo si dice che il codice genetico è degenerato. Questo implica che un singolo tRNA corrisponda per appaiamento di basi a più di un codone e che a ognuno degli amminoacidi corrisponda più di un tRNA: per alcuni amminoacidi esiste effettivamente più di una molecola di tRNA e inoltre la costituzione dell’anticodone di alcune molecole di tRNA è tale da esigere l’appaiamento accurato delle basi solo nelle prime due posizioni del codone mentre si tollera una discordanza nella terza base. Tale fenomeno viene definito oscillazione del codice genetico. Il codone d’inizio di tutte le sintesi proteiche è AUG che riconosce un tRNA iniziatore recante la metionina (nei Procarioti la formilmetionina).
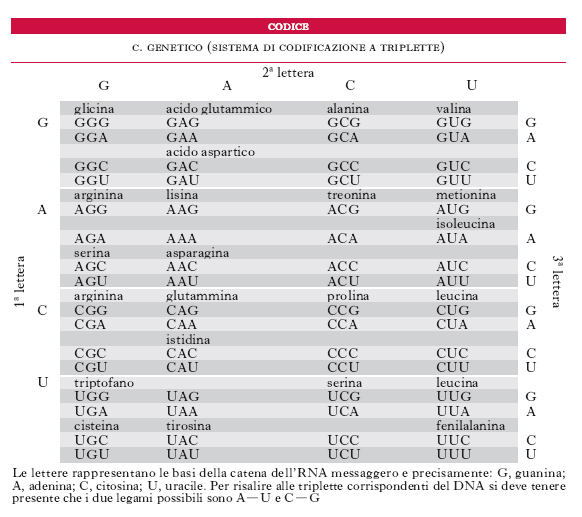
Utilizzando sostanze che inducono mutazioni nella sequenza dei nucleotidi si è potuto stabilire che il codice è a triplette ed è letto senza sovrapposizioni e senza interruzioni. Se sperimentalmente, mediante agenti mutageni che determinano sostituzioni di basi (mutazioni puntiformi) si modifica la natura di una base nel DNA di un codice a sovrapposizione, questa modificazione dovrebbe influire sulla natura di 3 codoni successivi e perciò su 3 amminoacidi successivi nella proteina corrispondente. Se il codice è del tipo non a sovrapposizione e ciascun nucleotide fa parte di un solo codone, allora è prevedibile che venga sostituito solo un amminoacido della proteina. Quest’ultima ipotesi è risultata quella vera. F.H.C. Crick e S. Brenner utilizzarono mutageni che provocano delezioni o inserzioni di nucleotidi (proflavina). Essi osservarono che, proprio perché il codice è del tipo non a sovrapposizione, una volta iniziata la lettura della sequenza, essa prosegue automaticamente a gruppi di 3 nucleotidi e se la sequenza è alterata per inserzione o delezione di un nucleotide, da quel punto in poi e per la rimanente parte del gene, la sequenza di codoni risulterà modificata rispetto a quella normale. Ne consegue che questo tipo di mutazioni (chiamate mutazioni frameshift o di scivolamento della cornice di lettura) provoca la formazione di una sequenza di amminoacidi diversi a partire dal punto in cui è avvenuta la delezione o l’inserzione di un nucleotide nel DNA. M.W. Nirenberg, S. Ochoa e H.G. Khorana arrivarono, verso la fine degli anni 1960, alla decifrazione completa dei diversi codoni del codice genetico (v. tab.).