
statistiche linguistiche
statistiche linguistiche
Definizione
Soprattutto con l’avvento dei corpora (➔ corpora di italiano) e degli strumenti informatici per consultarli, è divenuto possibile studiare con metodi statistici l’andamento di occorrenza di parole e di altre unità linguistiche in vari tipi di testi. Se nell’ambito della linguistica e della lessicografia computazionale tali statistiche linguistiche hanno un campo di applicazione molto ampio, il loro naturale punto di partenza è lo studio della frequenza di parole singole.
Sin dai lavori pionieristici dell’americano George Kingsley Zipf nella prima metà del XX secolo, si sa che la distribuzione della frequenza di occorrenza delle parole, in qualsiasi testo o collezione di testi, tende a seguire un andamento simile: un numero ristretto di parole (tipicamente, parole funzionali quali articoli e preposizioni) ricorre con altissima frequenza, seguito da una assai lunga coda di parole che capitano solo una volta (i cosiddetti hapax legomena; ➔ hapax) o hanno frequenza di occorrenza bassissima.
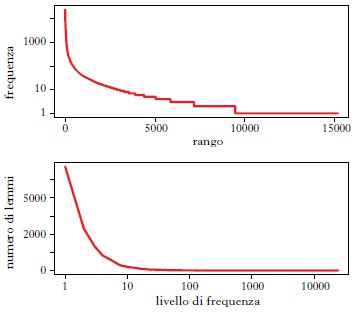
In fig. 1 illustriamo il tipico andamento zipfiano per i lemmi (ovvero le parole ricondotte alla forma in cui si troverebbero nel dizionario, ignorando dunque differenze di flessione; ➔ lemma, tipi di) del corpus LIP (1993) (circa 500.000 parole di italiano parlato; lemmario disponibile sul sito http://languageserver.uni-graz.at/badip/). Il primo grafico della fig. 1 riporta la frequenza dei lemmi (dove per frequenza intendiamo il numero di occorrenze di un lemma nel corpus prescelto) in funzione del loro rango (il lemma più frequente ha rango 1, il secondo rango 2, ecc.). Come si vede, le parole con i ranghi più bassi – ovvero le più frequenti – hanno un numero di occorrenze molto alto, che cala rapidamente all’aumentare del rango, mentre è presente una lunga serie di parole che compaiono soltanto una volta, o che sono comunque molto rare. Il secondo grafico illustra il medesimo andamento da un’altra prospettiva, ovvero raggruppando i lemmi per livelli di frequenza (cioè raggruppando i lemmi che capitano 1, 2, 3 volte, ecc.), e tracciando la distribuzione del numero di lemmi che corrispondono a ciascun livello di frequenza (sull’asse delle ascisse sono riportati i livelli di frequenza, su quello delle ordinate il numero di lemmi che hanno un certo livello di frequenza). Da questa prospettiva, emerge chiaramente l’alta proporzione di lemmi a frequenza 1 (poco meno del 40% del totale) e si vede come i lemmi che capitano 10 o meno volte costituiscano la grande maggioranza dei lemmi nel corpus (più dell’80% dei lemmi complessivi).
L’andamento illustrato in fig. 1 per il corpus LIP si riscontra anche in testi di dimensioni minori (per es., singole opere letterarie) e (molto) maggiori (corpora di centinaia di milioni o miliardi di parole), e riguarda non solo i lemmi, ma anche la distribuzione delle forme flesse (➔ flessione), di sintagmi (➔ sintagma, tipi di), di sequenze di parole e di costruzioni sintattiche, in tutte le lingue analizzate e indipendentemente dal tipo di testo (➔ testo, tipi di). Da Zipf in poi sono state proposte varie ‘leggi’ matematiche per esprimere l’andamento zipfiano, di cui la più famosa è appunto la legge proposta da Zipf stesso, che predice che la frequenza di occorrenza di una parola (o altra unità linguistica) in un testo/corpus è data da una costante divisa per il rango della parola medesima (Zipf 1949).
Frequenza e corpora
Dal punto di vista linguistico, l’andamento zipfiano mette in risalto la produttività del lessico delle lingue, che fa sì che anche corpora molto grandi non possano campionare l’intero universo delle parole che esistono, almeno in potenza, in una lingua. Da un punto di vista più pratico, tale andamento ha indotto linguisti e lessicografi a creare e utilizzare corpora sempre più grandi, che presentino un numero di istanze sufficienti allo studio di parole relativamente rare.
Si consideri lo schema seguente, che riporta i 10 lemmi più frequenti e un campione di 10 hapax legomena tra i molti estratti dal LIP:
lemmi più frequenti lemmi a frequenza 1
il (24.191) capolinea
di (19.915) formativo
essere (15.679) gettone
uno (13.129) grill
a (12.124) inarcare
e (10.188) Lipari
egli (;8.591) mattanza
non (8.480) sottosviluppo
in (8.132) tosse
che (7.786) valorosamente
Per quel che riguarda i lemmi più rari, se la bassissima frequenza di lemmi quali inarcare o sottosviluppo può in effetti essere indicativa del loro scarso utilizzo nella lingua parlata campionata dal LIP, per termini come capolinea, gettone, grill o tosse l’estrema rarità sembra piuttosto dovuta al fatto che il corpus non ha dimensioni o articolazione interna sufficienti a campionarli in maniera significativa. Se un corpus ha molti hapax, possiamo dedurne che, ampliandolo, troveremmo altri hapax, ovvero parole che non si trovavano nel campione originario. In effetti, nel LIP non troviamo alcuna occorrenza di parole intuitivamente non rarissime quali cannone, vena o abbaiare.
Un lessicografo o linguista che volesse studiare i contesti di termini come tosse o vena non potrebbe dunque farlo rivolgendosi a un corpus come il LIP. In un corpus più ampio, come quello di «La Repubblica» (circa 325 milioni di parole di italiano giornalistico; per i dettagli, ➔ corpora di italiano; cfr. il sito http://sslmit.unibo.it/repubblica/), il lemma tosse occorre 933 volte, vena 4599, e gli hapax sono termini che in effetti sembrano molto rari anche all’intuizione (per lo più, parole dalla forma complessa quali ininfluenzabile o non-costrizione, o prodotti di errori nell’elaborazione del corpus). Quindi, un corpus di alcune centinaia di milioni di parole può bastare a studiare il comportamento di una buona proporzione dei lemmi semplici di una lingua come l’italiano, anche se per studiare fenomeni particolari quali i ➔ neologismi, o unità linguistiche più complesse della parola, neppure un campione così grande sarebbe probabilmente sufficiente.
Natura dei lemmi
Rivolgendo ora l’attenzione ai lemmi più frequenti del LIP riportati nello schema visto sopra, si nota che essi hanno una funzione meramente grammaticale, e come tali tendono a essere i medesimi in tutti i testi e corpora della lingua (per es., i lemmi più frequenti nel corpus di «La Repubblica» sono esattamente gli stessi che nel LIP, fatte salve alcune differenze derivanti dal diverso metodo di riconduzione delle forme flesse ai lemmi).
Dunque, studiare le parole più frequenti in assoluto in un testo o corpus porta raramente a osservazioni interessanti. Si utilizzano invece misure d’associazione statistica che, data la frequenza di occorrenza di lemmi (o altre unità linguistiche) in due o più corpora, permettono di identificare i lemmi che capitano in un certo corpus con frequenza statisticamente superiore a quella attesa sulla base della frequenza assoluta dei lemmi e delle dimensioni dei corpora.

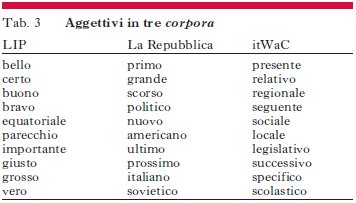
Utilizzando questo metodo (più precisamente, la misura d’associazione scelta è la log likelihood ratio, molto comune in linguistica computazionale), e confrontando il LIP, «La Repubblica» e itWaC (un corpus di più di un miliardo e mezzo di parole campionato dal web; cfr. http://wacky.sslmit.unibo.it), si hanno gli schemi riprodotti nelle tabb. , 2 e 3, che contengono rispettivamente i nomi, verbi e aggettivi che sono risultati più caratteristici di ciascun corpus paragonato agli altri (e dunque, nel limite in cui tali corpora sono campioni affidabili dei rispettivi linguaggi, dell’italiano contemporaneo parlato, giornalistico e sul web).
Questi schemi valgono semplicemente come esempi delle potenzialità dei metodi statistici applicati all’analisi dei testi; anche se va notato come essi facciano già emergere che il web, almeno come campionato in itWaC, deve contenere grandi quantità di testi legali e amministrativi.
Per una rassegna più approfondita dello studio statistico degli andamenti di frequenza nei testi, cfr. Baroni (2009), e per un panorama più ampio ma accessibile di vari metodi statistici applicati all’analisi del linguaggio, incluso lo studio della co-occorrenza di termini, cfr. Lenci, Montemagni e Pirrelli (2005).
Fonti
LIP (1993) = De Mauro, Tullio et al., Lessico di frequenza dell’italiano parlato, Milano, ETAS libri (http://badip.uni-graz.at/).
Studi
Baroni, Marco (2009), Distributions in text, in Corpus linguistics. An international handbook, edited by A. Lüdeling & M. Kytö, Berlin, Mouton de Gruyter, 2 voll., vol. 2º, pp. 803-821.
Lenci, Alessandro, Montemagni, Simonetta & Pirrelli, Vito (2005), Testo e computer. Elementi di linguistica computazionale, Roma, Carocci.
Zipf, George K. (1949), Human behavior and the principle of Least-Effort, Cambridge (Mass.), Addison-Wesley.