
DNA
Dna
L'acido deossiribonucleico (DNA) costituisce, con l'acido ribonucleico (RNA), la classe di polimeri informazionali definita acidi nucleici, componenti fondamentali delle strutture viventi. Tra tutte le molecole biologiche soltanto gli acidi nucleici possiedono la potenzialità di autoduplicazione che permette la replicazione e la trascrizione dell'informazione chimica in essi contenuta. Altri polimeri costituenti fondamentali delle strutture biologiche, quali le proteine e i polisaccaridi, sono privi di tale capacità e, pur dotati di comparabile complessità polimerica strutturale e informazionale, di ricchissima informazione chimica e di grande flessibilità funzionale, non sono in grado di rivestire un ruolo genetico. Questo ruolo è legato alla particolare organizzazione strutturale degli acidi nucleici e alle proprietà chimiche, fisiche e topologiche sia dei suoi costituenti sia delle macromolecole considerate nel loro insieme.
Struttura dei componenti
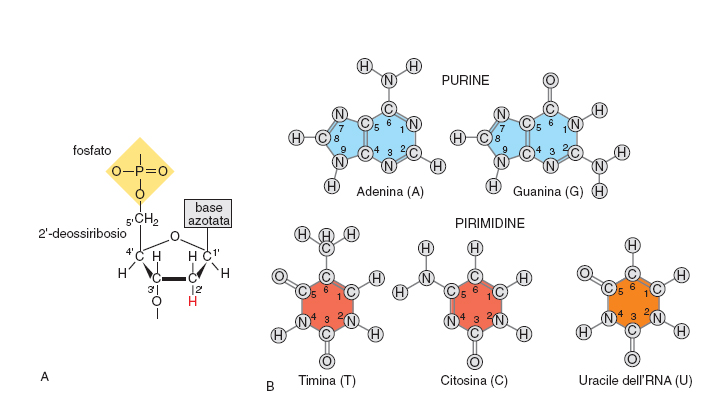
La struttura di base degli acidi nucleici è costituita dalla successione di monomeri legati tra loro a formare polimeri che, nei sistemi biologici, possono essere di dimensioni molto diverse, da poche unità fino a catene formate da centinaia di milioni di componenti. La struttura dei monomeri, che con la loro unione compongono il DNA, è schematizzata in fig. 1. Il monomero fondamentale del DNA è costituito da tre elementi: uno zucchero, un gruppo fosfato, una base azotata. Lo zucchero è un composto ciclico a cinque atomi di carbonio (il 2'-deossiribosio, mostrato in fig. 1a). Nel RNA questo zucchero è sostituito dal ribosio, diverso per avere un gruppo ossidrilico OH in posizione 2'. A questo zucchero si unisce in posizione emiacetalica 1' una delle quattro basi azotate (mostrata in fig. 1B), a formare un nucleoside. Le quattro basi presenti nel DNA sono due purine (Guanina e Adenina) e due pirimidine (Citosina e Timina) normalmente indicate con i loro acronimi G A C T (fig. 1b). Il RNA sostituisce l'Uracile (U) alla base Timina. Le purine sono legate al carbonio 1' dello zucchero attraverso l'azoto 9, le pirimidine attraverso l'azoto 1. Se al nucleoside si lega un residuo fosfato, in genere sull'ossidrile del carbonio 5', si ottiene un nucleotide. Il carattere acido del DNA è dovuto alla forte acidità del gruppo fosforico (costante di dissociazione pKa≅1).
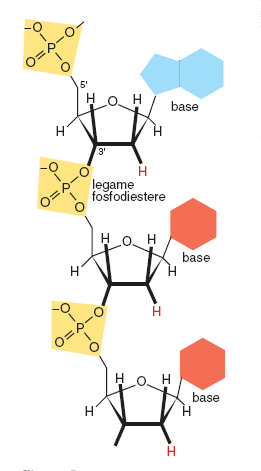
La polimerizzazione avviene attraverso la formazione di un legame tra il gruppo fosfato unito alla posizione 5' del 2'-deossiribosio e il gruppo 3' ossidrilico di un'unità precedente. Si forma così un legame detto fosfodiestere tra due residui monomerici. Questo legame può ripetersi un numero indefinito di volte, a formare l'eteropolimero DNA. È importante considerare che l'eteropolimero è formato da una parte costante e ripetitiva (lo scheletro, costituito dall'alternanza di gruppi fosfato e zuccheri uniti tra loro dai legami fosfodiesterici) e una parte variabile (le basi azotate puriniche o pirimidiniche legate alla posizione 1' dello zucchero). L'informazione genetica è resa possibile dalla possibilità combinatoria sostanzialmente infinita del susseguirsi delle quattro basi azotate che costituiscono la parte variabile. È inoltre importante considerare che il polimero nucleico è caratterizzato dal susseguirsi alternato e in sostanziale equilibrio di gruppi a carattere acido (i fosfati) e basico (le basi azotate).
Proprietà generali
L'eteropolimero è direzionale, è chimicamente instabile sia nella componente costante sia in quella variabile, è dotato di forte autocomplementarietà speculare. La direzionalità del DNA deriva dalla asimmetria della struttura dello zucchero (quattro atomi di carbonio all'interno della struttura ciclica, il quinto all'esterno) e dalla posizione del gruppo fosfato, legato all'atomo di carbonio 5'. La polimerizzazione avviene per formazione del legame fosfodiestere tra il fosfato legato in 5' di un nucleotide e il carbonio 3' di un altro nucleotide. La catena che si forma ha quindi una estremità iniziale in 5' e una estremità finale in 3'. Questa direzionalità strutturale e di sintesi 5'→ 3' del DNA è rispettata nella direzionalità della informazione genetica in esso contenuta e nella direzionalità della sua lettura da parte degli enzimi deputati alla sua replicazione (DNA polimerasi) ed espressione trascrizionale (RNA polimerasi). L'instabilità della catena polimerica è dovuta soprattutto alla possibilità di rottura del legame tra basi azotate e zucchero (il legame β-glicosidico) e di quello fosfoesterico tra zucchero e fosfato. Se posti in acqua, sia il DNA sia l'RNA vanno infatti rapidamente incontro a degradazione. Il ruolo genetico dei polimeri nucleici, legato alla possibilità di una loro sopravvivenza per tempi sufficientemente lunghi, è basato sull'azione stabilizzante esercitata da meccanismi di varia natura; principali tra questi sono l'autoprotezione dovuta alla formazione di strutture secondarie sia nel DNA sia nel RNA, e l'interazione con proteine specifiche. L'instabilità chimicamente intrinseca del DNA non costituisce però soltanto un limite alla sua sopravvivenza in quanto molecola complessa; l'esistenza di meccanismi di riparazione sia a carico della parte variabile (le basi) sia a livello dello scheletro zucchero-fosfato è la chiave di fenomeni biologici fondamentali quali la mutazione e il loro controllo, la ricombinazione genetica, la trasposizione e, più in generale, l'evoluzione stessa. Un ulteriore fattore intrinseco di instabilità è dovuto alla tautomeria delle basi. In fig. 1 le basi sono rappresentate nelle loro forme più frequenti. Accanto a queste esistono forme strutturalmente alternative, presenti soltanto per una frazione di tempo molto breve. Nonostante la sussistenza statisticamente limitata, una forma tautomerica può essere fonte di mutazione, soprattutto se presente al momento della replicazione del polimero. Anche per la tautomeria è importante riconoscere il doppio ruolo di destabilizzazione dell'informazione codificata nella sequenza nucleotidica e di promotore di evoluzione. La capacità delle basi nucleiche di formare legami idrogeno conferisce al DNA la possibilità di stabilizzarsi in doppia elica. Un legame idrogeno si forma tra un atomo di idrogeno covalentemente legato a un gruppo donatore (come −OH o =N−H) e una coppia di elettroni liberi di un gruppo accettore (come O=C−oppure N≡). Questo legame, della lunghezza media nelle molecole di importanza biologica di 0.29 nanometri (nm), possiede allo stesso tempo proprietà sia di interazione covalente sia di interazione non covalente, è considerato un legame debole ed è altamente direzionale, tendendo a formare angoli di 180°. Queste sue caratteristiche, e l'abbondanza nelle basi nucleiche di gruppi che possono formarlo, fanno sì che due filamenti di DNA posti in prossimità tendano a interagire in modo stabile e dipendente dalla sequenza nucleotidica che li forma.
La struttura
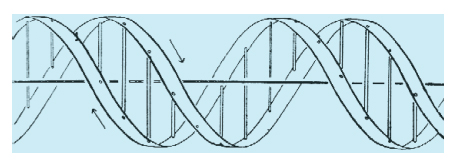
L'Adenina forma due legami idrogeno con la Timina, la Guanina ne forma tre con la Citosina. (fig. 2) Questa specificità di interazione locale determina la specificità di interazione globale delle sequenze polimeriche. L'interazione avviene in modo stericamente compatibile tra una sequenza (per es., 5' ATGCAATTGG 3') e la sua complementare (3' TACGTTAACC 5') e darà luogo alla formazione di un doppio filamento, stabilizzato in questo caso da 24 legami idrogeno, autocomplementare e, rispetto alla sequenza, speculare. L'interazione è ulteriormente stabilizzata e spazialmente organizzata dalla idrofobicità delle basi che in soluzione acquosa tendono a disporsi all'interno del doppio filamento, e dalla idrofilicità dei gruppi fosfato che si dispongono all'esterno. La forma più stabile di interazione è in forma di elica, come descritto da J.D. Watson e F.H.C. Crick in un articolo del 1953 (fig. 3). La frase finale di questo scritto illustra in modo conciso la proprietà principale della struttura a doppia elica complementare che il DNA assume per ragioni chimiche intrinseche: "non è sfuggito alla nostra attenzione che lo specifico appaiamento che abbiamo postulato suggerisce immediatamente un possibile meccanismo di copiatura per il materiale genetico".

I parametri strutturali che caratterizzano la doppia elica sono riportati nella tabella. La fig. 4 illustra con modelli molecolari compatti le strutture di doppie eliche di DNA in conformazione B, A e Z. L'esistenza di conformazioni diverse è dovuta al fatto che il DNA non è una struttura perfettamente regolare e omogenea. Al contrario, la sua organizzazione tridimensionale è caratterizzata da estrema variabilità strutturale, sia locale sia a lungo tratto, da flessibilità potenziale e differenziale in funzione della sequenza nucleotidica, da curvature effettive caratterizzate da diversi gradi di rigidità, da forte dinamica, da capacità di cambiare conformazione in funzione sia dell'ambiente chimico-fisico nel quale è immerso sia della interazione con altre macromolecole, segnatamente proteiche.
La struttura del DNA così come definita originariamente nel modello della doppia elica Watson-Crick (fig. 3) è soltanto un modello astratto. Nella realtà il DNA oscilla punto per punto all'interno di un insieme di conformazioni alternative. Tre di queste conformazioni sono riportate in fig. 4. Altre conformazioni osservate e completamente diverse dalla doppia elica sono: strutture cruciformi, strutture anisomorfe, strutture ad ansa, strutture a elica singola o a elica tripla e quadrupla. L'informazione strutturale della macromolecola DNA non è limitata quindi alla possibilità di avvolgere a elica un filamento intorno all'altro in modo regolare e ripetitivo. La doppia elica Watson-Crick è semplicemente la struttura più stabile e più frequente all'interno di un vasto numero di possibilità alternative.
Un ulteriore livello di complessità strutturale e di ricchezza informazionale del DNA è quello topologico. Nelle sue forme biologiche (cromosomi, episomi) il DNA non presenta estremità libere, soprattutto allo scopo di diminuire la possibilità della propria degradazione. Le estremità vengono evitate creando molecole circolari (come in moltissimi genomi virali), oppure evolvendo strutture terminali, dette telomeri, molecolarmente richiuse su sé stesse (come nei cromosomi), oppure legando sull'estremità della molecola di DNA singole proteine in modo covalente (come nel genoma di adenovirus). In ognuno di questi casi viene creato un sistema chiuso all'interno del quale si instaurano proprietà topologiche. Una struttura topologicamente chiusa è in grado di accumulare energia torsionale. Ciò fa sì che nel DNA il modo in cui un'elica si avvolge intorno all'altra può variare, aumentando o diminuendo la torsione locale. L'informazione topologica consiste essenzialmente nel modulare l'esposizione verso l'esterno (regolandone quindi l'accessibilità funzionale) dell'informazione genetica contenuta nella sequenza delle basi, che, come mostrato in fig. 4, sono normalmente confinate nella parte interna e più difficilmente accessibile della struttura.
I codici
La determinazione della struttura della doppia elica ha immediatamente posto la domanda sul come l'informazione biologica venga codificata. La codificazione è basata sulla capacità di contenere (quasi) ogni immaginabile combinazione delle basi i cui acronimi sono le lettere ATGC. È possibile quindi elaborare messaggi con meccanismo digitale. L'informazione del DNA è dunque informazione primaria, determinata dalla sequenza nucleotidica. Il dizionario di lettere di DNA che codifica gli aminoacidi è definito codice genetico. A questo codice sul DNA se ne affiancano altri.
Codice strutturale. Determina in quale delle sue possibili conformazioni (B, A, Z, cruciforme ecc.) il DNA sarà più stabile.
Codice topologico. Determina, tra l'altro, le proprietà di accessibilità locale.
Codice epigenetico. È dato dall'insieme di modificazioni chimiche delle basi della sequenza e dalle modificazioni chimiche delle proteine regolatrici che con il DNA interagiscono. Questo codice, la cui rilevanza nella regolazione dell'espressione dell'informazione contenuta nel DNA è in corso di studio, è in grado di modificare profondamente il comportamento del genoma, concerne per definizione tutte le modificazioni genetiche che non comportano mutazione, è sufficientemente stabile da trasmettersi attraverso le generazioni.
Codice regolativo. L'espressione e il silenziamento dei geni vengono regolati da sequenze nucleotidiche specifiche e complesse. Insieme al codice genetico sensu strictu, questo codice costituisce il codice digitale del sistema informazionale del DNA.
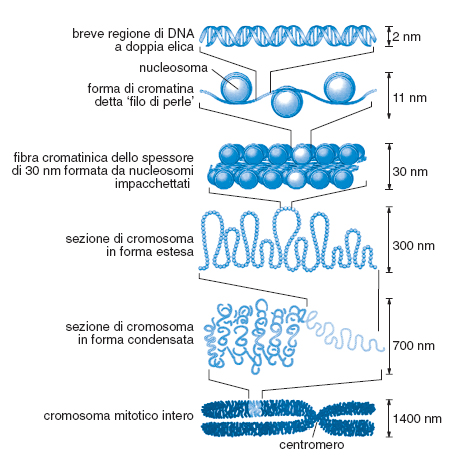
Codice cromatinico. La complessità nucleotidica dei genomi è molto alta. Il genoma aploide di una cellula animale varia - come ordine di grandezza indicativo - tra i 108 e i 1010 nucleotidi. Per poter ordinare fisicamente e funzionalmente questa massa di materiale si è evoluto un sistema di organizzazione detto cromatina (fig. 6). Nel loro insieme, il codice strutturale, quello topologico e quello cromatinico costituiscono un insieme di informazioni definite analogiche.
Partendo dall'identificazione di questi codici multipli, gli studi sul DNA si sono sviluppati in direzioni molto diverse tra loro. Ciò ha portato a sviluppi conoscitivi e applicativi totalmente imprevedibili; ne è esempio l'uso del DNA come oggetto di nanotecnologia.
Le nanotecnologie vengono intese in modo differente a seconda del campo al quale si riferiscono: elettronico, medico, informazionale, analitico, scienza dei materiali. Esse hanno però in comune l'ambito dimensionale, il nanometro (nm, equivalente a 10−9m), all'interno del quale vengono definite le strutture e i meccanismi di interesse. Il fatto che il DNA sia in scala nanometrica, unito alle sue doti di molecola portatrice di informazione e capace di autoreplicazione, rende la sua doppia elica oggetto di elezione nella progettazione di nanostrutture. A questo vanno aggiunte la capacità di assumere direzione regolabile e quella di sviluppare interazioni intra- e intermolecolari di alta specificità. Tutto ciò questo ha fatto sì che il DNA abbia trovato applicazione nella progettazione di nanocircuiti elettronici, nello sviluppo di meccanismi di calcolo per la soluzione di problemi altrimenti non risolvibili dal punto di vista matematico, nella costruzione di elementi monomolecolari di elaborazione e trasmissione di informazione strutturale.
Il limite funzionale dei circuiti elettronici dei microchips in uso è costituito dal metodo fotolitografico con il quale essi vengono incisi sugli appropriati substrati semiconduttori. Il limite è dunque intrinsecamente dettato dalla lunghezza d'onda della luce usata. Minore è la lunghezza d'onda, più fine sarà il circuito e più capace sarà il microchip. Il problema posto dalla impossibilità di collimazione della radiazione X stabilisce il limite nell'ultravioletto profondo e impedisce l'ulteriore miniaturizzazione del sistema, bloccato subito al di sotto dei 100 nm. Circuiti sperimentali costituiti di filamenti di DNA trasformati in semiconduttori permettono di scendere a livello di 10 nm, potenzialmente aumentando di un ordine di grandezza l'efficienza della struttura.
L'uso del DNA come oggetto di calcolo è basato sulla tecnica della PCR (Polymerase Chain Reaction), metodo che permette di replicare una sequenza nucleotidica in modo logaritmico e sostanzialmente senza altri limiti se non quelli del volume a disposizione. Poiché si è in ambito nanometrico, il numero delle molecole coinvolte è altissimo. Associando valori numerico-simbolici alle sequenze nucleotidiche e inserendo nel sistema replicativo possibilità di sviluppo di sequenze alternative, si svolgono calcoli a velocità impensabili anche per i computer più potenti. Il principio metodologico del sistema è l'associazione di significati di calcolo a eventi monomolecolari modificabili. Il principio euristico è l'attribuzione di significati di codice diversi (numerico e molecolare) a una stessa struttura, usando un approccio darwiniano al calcolo.
Il codice topologico del DNA è alla base di fondamentali proprietà genetiche, terapeutiche, nanotecnologiche. La topologia, applicata al DNA, definisce una serie di proprietà caratteristiche dei sistemi chiusi. La doppia elica rifugge, per sua natura, dall'avere estremità libera: il doppio filamento tende a chiudere in qualche modo le proprie terminazioni. La ragione è l'instabilità dei legami chimici che tendono a mantenere unite le due eliche e che trova nelle estremità un punto di destabilizzazione preferenziale. La soluzione consiste, in tutti i sistemi naturali, nel chiudere in qualsivoglia modo un filamento nell'altro. Questo fine viene raggiunto con meccanismi diversi tra loro: con il legame covalente di proteine alle estremità dei filamenti (per es., nel genoma di adenovirus), con la creazione di estremità a sequenze coesive (come nel batteriofago λ); con telomeri a struttura complessa (come nella gran parte dei cromosomi eucariotici), con la circolarizzazione del filamento (come in moltissimi plasmidi e genomi virali). Un doppio filamento, se chiuso, ha proprietà strutturali e funzionali diverse da quelle di un doppio filamento aperto. Nella loro essenza geometrica queste proprietà fanno sì che il sistema sia deformabile in modi alternativi. Il DNA può così assumere conformazioni diverse: avvolgersi su sé stesso in un punto e aprire la doppia elica in un altro, nascondere la propria informazione di sequenza o esporla in modalità e in momenti differenti. Le proprietà topologiche fanno dunque sì che la doppia elica usi la propria energia torsionale distribuendola lungo la propria sequenza nucleotidica con meccanismi regolativi ed estremamente sensibili, moltiplicando e modulando la propria informazione. Poiché queste proprietà sono alla base dell'intensità di trascrizione genetica, e poiché la topologia è regolata da enzimi (le DNA topoisomerasi), i farmaci in grado di interferire selettivamente con questi enzimi sono potenti e specifici agenti antimicrobici e antitumorali.
Bibliografia
J.D. Watson, F.H.C. Crick, Molecular structure of nucleic acids. A structure of Deoxyribose Nucleic Acid, in Nature, 1953, 171, pp. 737-38;
C.R. Calladine, H.R. Drew, Understanding DNA, London 19992;
L. Hood, D. Galas, The digital code of DNA, in Nature, 2003, 421, pp. 444-48;
W. Wayt Gibbs, The unseen genome: beyond DNA, in Scientific American, 2003, 12, pp. 78-85;
B. Samorì, G. Zuccheri, DNA codes for nanoscience, in Angewandte chemie international edition, 2005, 44, pp. 1166-181.